Authors: Allen Huang, Andreas Kipf, Ryan Marcus, and Tim Kraska
Learned indexes have received a lot of attention over the past few years. The idea is to replace existing index structures, like B-trees, with learned models. In recent a paper, which we did in collaboration with TU Munich and are going to present at VLDB 2021, we compared learned index structures against various highly tuned traditional index structures for in-memory read-only workloads. The benchmark, which we published as open source including all datasets and implementations, confirmed that learned indexes are indeed significantly smaller while providing similar or better performance than their traditional counterparts on real-world datasets.
Since the initial release of SOSD, we’ve made a few additions to the framework:
- Added new competitors (ALEX and a C++ implementation of HistTree contributed by Mihail Stoian).
- Added synthetic datasets as well as smaller (50M rows) datasets.
- Reduced overhead of benchmarking framework further.
While SOSD certainly filled the gap of a standardized benchmark, we feel that due to the sheer number of papers in this area, there’s still a lot of discrepancies among experimental evaluations. This is mainly due to the fact that many implementations need to be tuned for the datasets and hardware at hand.
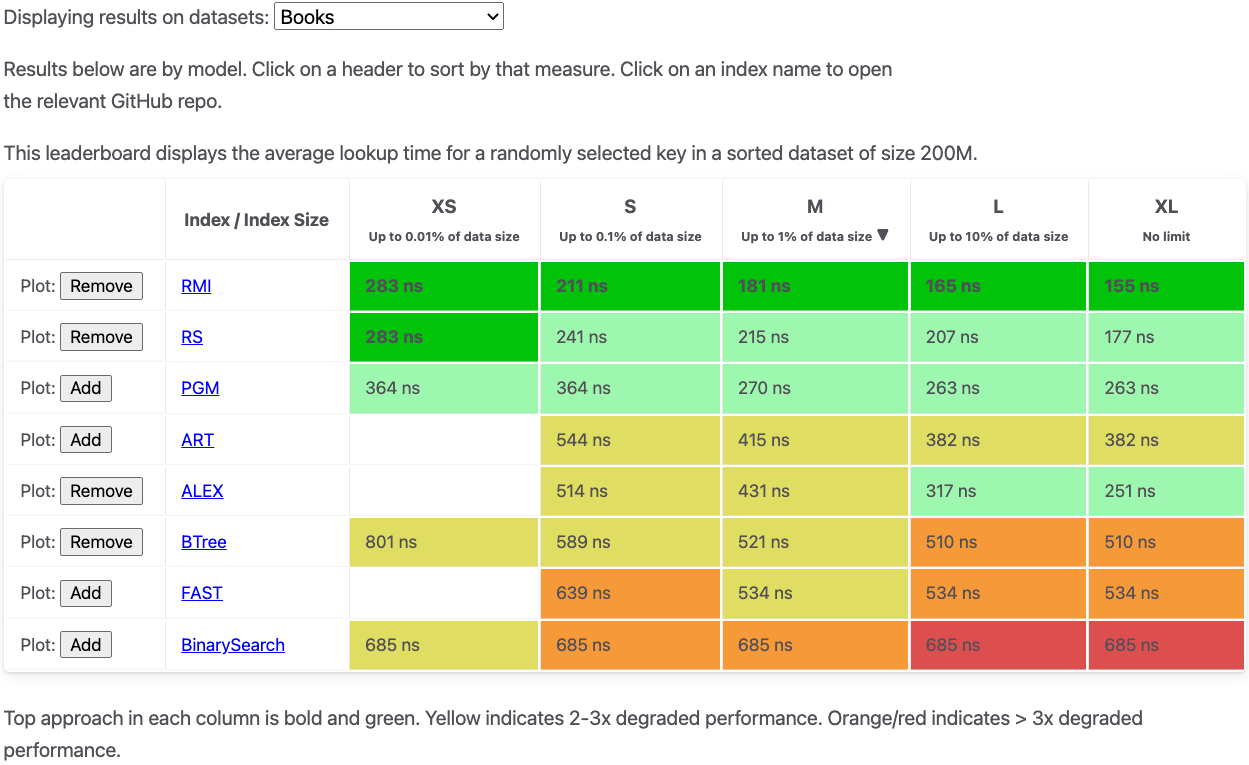
Today, we’re happy to announce the Learned Indexing Leaderboard, an ongoing indexing benchmark on various synthetic and real-world datasets based on SOSD. For each dataset, there are different size categories (e.g., M stands for an index size of up to 1% of the dataset size). We’ll be using the m5zn.metal AWS instance type for the leaderboard to ensure a common playing field.
We hope that our benchmark will receive contributions from the community (index implementations, datasets, and workloads) and can serve as a common benchmarking testbed.